testtrim: The Testing Tool That Couldn't Test Itself (Until Now)
Today, we’re going to deep-dive into the kind of thing you can only “invest” time on if you’re a single engineer working on a project with no supervision. I just finished a crazy complicated development effort in my project, testtrim, and all I want to do is talk about how surprised I am that it actually worked.
I’ve also published this article in a video form, if you’re more inclined to that format:
Context: What’s testtrim, again?
testtrim is an experimental project to optimize execution of software tests.
It works by:
- running your tests once, and
- analyzing test dependencies (via code coverage + syscall tracing).
Then, when any future software changes occur, it can use that analysis to select which tests need to be run to cover the software change.
I went into more detail on the code coverage side in an earlier post, but today it’s all about syscall tracing.
syscall Tracing
There are two types of dependencies that I want testtrim to find that require syscall tracing:
- reading files that are part of the repository, and
- accessing resources over the network.
If a test does either of those things, it requires some special handling to determine when the test needs to be run again. For example, if a file referenced by a test (eg. test_data/Fibonacci_sequence.txt) changes in the future, it would make a lot of sense to run the referencing test (eg. test_fibonacci_sequence).

The tool that I always reach for when I need to do syscall tracing is called strace. It’s a superpower to be able to use strace effectively, but it’s super easy to start with. You take a command that you want to run, and you throw strace at the beginning, and you get a record of all the syscalls that the command made:
$ echo "This is some text."
This is some text.
$ strace echo "This is some text."
... snip output ...
write(1, "This is some text.\n", 19) = 19
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
It took a couple weeks to develop the first draft of syscall tracing in testtrim, using strace. It was pretty straightforward engineering:
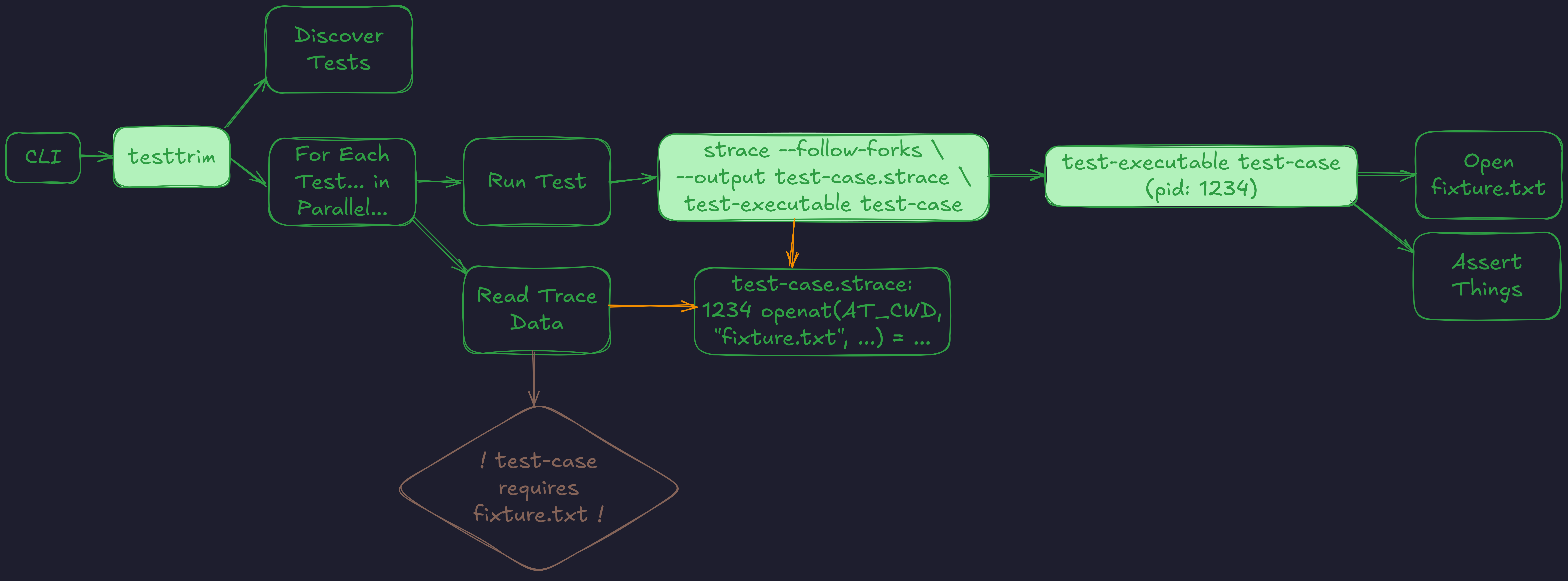
When you run testtrim from the command line:
- Discover Tests: testtrim finds all the tests in your project (
Discover Tests) - For Each Test, in Parallel…:
- It runs each test under
strace, with options including an output file (--output), and including all child processes (--follow-forks). - Open fixture.txt: When the test process (eg. pid 1234) performs a syscall like opening the file “fixture.txt”…
stracewrites a record to the output file.- Read Trace Data: After the test is completed, testtrim reads the data file and parses it,
- … from which it can interpret the syscalls into dependencies that are part of that test - like in this case, that “test-case” requires “fixture.txt”.
- It runs each test under
If a file referenced by a test is part of the project’s repo, then it will become a dependency – and in the future, if it’s changed, then “test-case” needs to be rerun.
But, Nested syscall Tracing
But, here’s the catch: I want to use testtrim to test testtrim. I’ve always been a fan of “dogfooding” – although there are cases where it doesn’t make sense. But as a software developer working on a software development tool, it’s a pretty natural fit!
testtrim has integration tests which use miniature test projects to verify that testtrim works. Once syscall tracing was introduced, these tests prevented testtrim from running on its own project because you can’t use strace on a process that is already being traced. (It would work if you weren’t using --follow-forks, but then the trace would be arbitrarily incomplete.)

Honestly, understanding the roadblock this posed was a really disappointing moment for me. syscall tracing worked - my miniature test projects showed it - and there was apparently nothing blocking me from using it on other projects. But it was always a goal of mine for testtrim to work on itself. In addition to be emotionally disappointing, I think it was also important to the project to be able to use testtrim on itself:
- That would allow me to work out kinks and bugs involved in real-world usage.
- It would generate the dataset that would prove (or disprove 🤷) its own value in test target reduction.
- And I didn’t want to be a hypocrite trying to promote something that I didn’t even use myself.
It had to be solved.
Nested Tracing v1: What could go wrong?
After a bit of disappointment, I had a lightbulb moment: I control both of these programs. Can I just make them cooperate? The “tracer” knows everything that all of these processes are doing - it’s just a simple matter of getting the data from testtrim over to the integration test.
So, first pass… ah, I was so naive…
- Inject an environment variable when running a test child that contains the path to the strace output file.
- In the test, recognize the environment variable and:
- Do not use
strace. - Read the strace output file contained in the environment variable.
- Filter out the file to just the process IDs that are relevant to the completed test.
- Do not use
This does somewhat work - both trace points are able to identify the knowledge that they need.
But, if you can see the problem with this approach, then you are very, very clever. I, on the other hand, did not.
You see, every time the child goes to read data from the strace output file, it has to perform a read syscall… which goes back to the parent’s strace… which gets written to the output file… which then the child has to read…
sigh
It’s not quite an infinite loop. (Well, it was when I first ran the code, of course.) But there is an exit condition that can be added in: the integration test can stop reading the trace file once it finds the process exit record for its test cases. For example, in the diagram above the test was process 4321, and so process 1234 can stop when it hits the exit condition for 4321. So not infinite, but incredibly magnified.
The performance of this solution was very bad - the more tests that needed to be run in a subprocess, the more times it was re-reading the syscall data, which included every syscall involved in the last re-read of the data. When combined with multiple parallel tests running, there’s a geometric growth in strace output that needs to be read.
So, I came up with an alternative that seemed far more promising… for a while.
Nested Tracing v2: This Will Work For Sure!
strace has an option called --output-separately. This changes the output location to a directory rather than a file, and outputs each process that was traced into its own file.
This would work with testtrim wonderfully:
- Use
--output-separatelyto write one file per process. - Pass the location of the files to the child process.
- When the integration tests’s test process completes, it can read just the child PID’s file – which is a terminated subprocess, avoiding the syscall amplification.
There is, of course, a complication. It seems small, and then it becomes really messy.
We can’t just read the file with the child’s PID, but we also need to read any subprocesses of that process, and subprocesses of those processes.
Like I said, seems simple, right? Read the child PID’s file, and since it is a record of syscalls, simply note any processes that it spawned and read those files as well. Repeat as necessary.
This seemed great! For a bit.
But the subtle problem is that processes aren’t independent. What software developers would usually call a “process” is a program execution which is operating independently; and we’d use the term “thread” to refer to multiple concurrent execution within a process. But in the Linux kernel, and in strace’s output, a thread is a process. strace outputs each thread to a separate output file… but they have shared state that is relevant to our syscall tracing.
To keep things simple, we’ll use the current working directory as an example. Let’s say pid 4321 and pid 4322 are threads, and our strace output shows:
$ cat test-case.strace.4321:
execve("test-executable", ["test-case"]) = ?
clone(... CLONE_THREAD, ...) = 4322
...snip...
openat(AT_CWD, "fixture.txt", ...) = ...
...snip...
+++ exited with code 0 +++
$ cat test-case.strace.4322
...snip...
chdir("../test_data")
...snip...
+++ exited with code 0 +++
We know:
- PID 4321 opened the relative file path
fixture.txt - PID 4322 changed the current working directory to
../test_data
But we don’t know what order those two events happened in. The order of them completely changes which file was accessed by the test.
After I started sending strace data to separate files, I no longer know the order of the events in them. And if they can affect shared state, like the current working directory of the process, or access shared file descriptors between the threads, the effective events of the process are lost.
I took a brief look at using strace’s timing outputs in order to provide ordering, but first it seemed sketchy in terms of accuracy, and second the performance of strace gets much, much worse. It needs to constantly access the system clock, so that performance drop makes sense.
Nested Tracing v3: syscall Tracing Sans syscalls?
Getting to a solution that met all the criteria required a little backtracking, one simple tweak, and one complicated tweak.
First, I reverted to the single output stream, rather than --output-separately - other than timestamps, this was the only way I was going to get an ordered view of the syscalls.
The simple tweak was to start to stream the data from strace into the parent process through a FIFO pipe, which allowed the parent process to parse and understand the asynchronously while waiting for the subprocess to finish. Now that data was live in the parent process, and I just needed to get access to that event stream from the child… without using syscalls. (Well, syscalls to get things “started” were fine, but there had to be no syscalls involved in reading data.)
Simplifying a few details, the architecture ends up looking like this:
- The testtrim process opens a UNIX socket, and passes the address down to subprocesses through an environment variable.
- When an integration test wants to start a test-case with nested tracing, it connects to the testtrim process, and sends a request to subscribe to the PID of the child process.
- testtrim starts a shared-memory buffer and begins to store any syscalls from the PID of the child. This is where the live connection through the pipe to strace matters - we’re able to instantly connect into that data stream and copy it into the buffer.
- testtrim sends back to the test process an address for the shared memory buffer.
- On an ongoing basis, testtrim writes syscall data to the shared buffer, and the test process reads it out. A ring buffer is used so that we can have a fixed memory allocation which supports the continuous stream between the two processes.
There are are few tricky parts of the implementation:
- When a child process starts a test, we can’t miss syscalls - so we need to synchronize starting up the child process, subscribing to the events, receiving acknowledgement that we subscribed, and then allowing the child process to actually start.
- We can’t guarantee the order of syscalls coming out of strace: a child process’s
cloneorforkor whatever might begin in the syscall stream, and then syscalls from that child process would appear, and then the finish of the clone/fork/etc could be emitted. So testtrim needs to occasionally “lightly reorder” the syscalls during process startup, just to ensure that subprocesses are recognized correctly. - When a test process terminates, we need to make sure that all the syscalls are delivered to the child process, and none are still in-memory. To accomplish this, the testtrim process over here keeps an eye out for process exit messages and sends an EOF marker into the shared memory buffer.
Conclusion
Does it work?
Yes.
It took more than a few passes to get the synchronization logic correct, and with this complexity there might still be a surprise or two to learn. But, it functions!
With this design, nested strace data collection is possible, and the order of syscalls is preserved such that we can recognize dependencies between threads like changing the working directory on one thread, and opening a file on another.
This has been the final piece in the puzzle to getting testtrim to be able to run on its own project, in its own CI. It’s a shame that the nested logic will never be useful for anything else, but it’s pretty cool.
There’s one more neat thing that testtrim is doing with syscall tracing which is more generally applicable to other test projects - but that seems like a topic for another post. Until then, hope you’ve enjoyed this deep-dive!